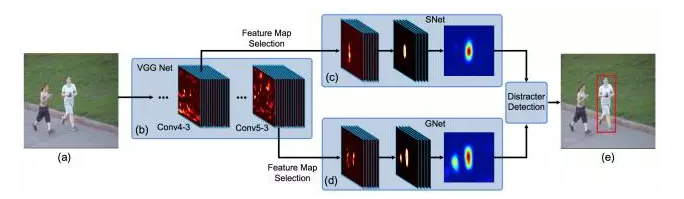
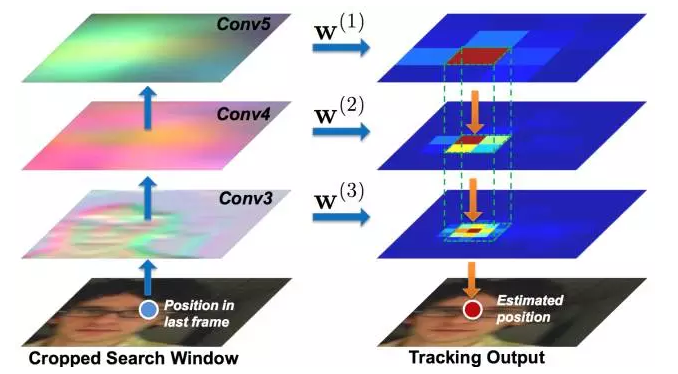
Lei Feng, net: According to Xu Xiaqing, the author of this article, the Institute of Computing Technology, Chinese Academy of Sciences VIPL group master student, instructor Chang Hong, associate researcher. The research direction is deep learning and computer vision (target tracking, etc.). Before we start this article, we first look at the three pictures given above, which are the first 1, 40, and 80 frames of the same video. After a runner's bounding box is given in the first frame, the subsequent 40th, 80th frame, bounding-box still accurately circles the same runner. The above is actually the process of visual object tracking. Target tracking (specifically, single-target tracking) refers to: giving the target the initial state (such as position, size) in the first frame of the video, and automatically estimating the state of the target object in the subsequent frame. The human eye can easily follow a specific target for a period of time. But for the machine, this task is not simple, especially in the tracking process there will be various complicated situations such as the violent deformation of the target, the occlusion of other targets or the interference of similar objects. In the past decades, the research of target tracking has made great progress. Especially since various machine learning algorithms have been introduced, the target tracking algorithm presents a flourishing situation. Since 2013, in-depth learning methods have begun to show off in the field of target tracking, and they have gradually surpassed traditional methods in performance and have made tremendous breakthroughs. This paper first briefly introduces the mainstream traditional target tracking method, then introduces the deep learning based target tracking algorithm, and finally summarizes and prospects the application of deep learning in the field of target tracking. Currently tracking algorithm can be divided into production (generative model) and two categories discriminant (discriminative model). The production method uses a generative model to describe the apparent features of the target, and then minimizes the reconstruction error by searching for candidate targets . The most representative algorithms are sparse coding, online density estimation and principal component analysis (PCA). The production method focuses on the characterization of the target itself, ignores the background information, and tends to drift when the target itself changes dramatically or is obstructed. In contrast, discriminative methods distinguish targets and backgrounds by training classifiers . This method is also often referred to as tracking-by-detection. In recent years, various machine learning algorithms have been applied to discriminant methods, among which are multiple instance learning methods, boosting and structured SVM. The discriminative method is more robust because it significantly distinguishes the information of the background and the foreground, gradually occupying the mainstream position in the target tracking field. It is worth mentioning that most current methods for tracking deep learning goals are also attributed to discriminatory frameworks. The correlation filter uses clever application of Fast Fourier Transform to achieve a significant speed increase. At present, there are many extension methods based on correlation filtering, including Kernelized Correlation Filter (KCF) and Scaled Correlation Filter (DSST). Different from the trend of deep learning in the visual field of detection, recognition, etc., the application of deep learning in the field of target tracking is not easy. The main problem lies in the lack of training data : one of the magic of the depth model comes from effective learning of a large number of labeled training data, and the target tracking only provides the first frame of the bounding-box as training data. In this case, it is difficult to start a deep model training from scratch on the current target. At present, there are several ways to solve this problem based on the deep learning target tracking algorithm. The following introduction will be based on different ideas. At the end, we will introduce the recurrent neural network in the current tracking field to solve the target tracking problem. New ideas. In the case that the target tracking training data is very limited, pre-training is performed using auxiliary non-tracking training data to obtain a general representation of the characteristics of the object. In actual tracking, by using the limited sample information of the current tracking target The pre-training model fine-tune enables the model to have stronger classification performance for the current tracking target. This migration learning idea greatly reduces the need for tracking target training samples and improves the performance of the tracking algorithm. Representative works in this area include DLT and SO-DLT, both from Dr. Wang Nayan, Hong Kong University of Science and Technology. DLT (NIPS2013) Learning a Deep Compact Image Representation for Visual Tracking DLT is the first tracking algorithm to apply depth models to single-target tracking tasks . Its main idea is shown above: (1) Unsupervised off-line pre-training on a large-scale natural image data set such as the Tiny Images dataset using a stacked denoising autoencoder (SDAE) to obtain universal object characterization capabilities. The pre-trained network structure is shown in (b) above. A total of 4 noise reduction self-encoders are stacked. The noise reduction self-encoder adds noise to the input and obtains more robust features by reconstructing the noise-free original image. expression ability. The bottleneck structure design such as SDAE1024-2560-1024-512-256 also makes the obtained features more compact. (2) After the online tracking part of the structure shown in Figure (c) below, take off-line SDAE encoding part of the overlay sigmoid classification layer composed of the classification network. The network at this time did not acquire the specific ability to express the current tracked object. At this point, using the first frame to obtain positive and negative samples, fine-tune the classification network to obtain a more targeted classification network for the current tracking target and background. During the tracking process, the current frame is extracted using a particle filter to pick up a batch of candidate patches (equivalent to the proposal in detection). These patches are input into the classification network, and the highest confidence level becomes the final prediction target. (3) On the model updating strategy where the target tracking is very important, the paper adopts the method of limiting the threshold, that is, when the highest confidence among all the particles is lower than the threshold, it is considered that the target has undergone a relatively large apparent change, and the current classification The network is no longer adaptable and needs to be updated. Summary : As the first tracking algorithm for applying deep network to single-target tracking, DLT first proposed the idea of ​​“offline pre-training + online fine-tuningâ€, which largely solved the problem of insufficient training samples in tracking and was proposed in CVPR2013. Ranked 5th among 29 trackers on the OTB50 dataset. However, there are some shortcomings in DLT itself: (2) The training goal in the off-line phase is image reconstruction, which is very different from the goal of on-line tracking to distinguish the target from the background. (3) SDAE's fully connected network structure makes it incapable of characterizing the target. Although a 4-layer depth model is used, the effect is still lower than some traditional tracking methods using artificial features such as Struck. SO-DLT (arXiv2015) Transferring Rich Feature Hierarchies for Robust Visual Tracking SO-DLT continued DLT's strategy of using non-tracking data pre-training and on-line fine-tuning to solve the problem of insufficient training data during the tracking process. At the same time, it also greatly improved the problems existing in DLT. (1) Use CNN as a network model to obtain features and classifications. As shown in the above figure, SO-DLT uses a AlexNet-like network structure, but it has several major features : First, the input is reduced to 100100 for the size of the tracking candidate area, instead of 224,224 in the general classification or detection task. Second, the output of the network is a 5050 size, a probability map with a value between 0-1, and each output pixel corresponds to the area of ​​the original map 22. The higher the output value, the higher the probability of the point in the target bounding box. The higher is also. This approach uses the structured information of the picture itself to facilitate the direct determination of the final bounding box from the probability map and avoid the input of hundreds of proposals to the network. This is also the origin of the SO-DLT structured output name. Thirdly, spatial pyramid pooling in SPP-NET is used between the convolutional layer and the fully connected layer to improve the final positioning accuracy. (2) Use ImageNet 2014's detection dataset in off-line training to enable CNN to distinguish between object and non-object (background) capabilities. The SO-DLT online tracking pipeline is shown above: (1) When processing the t-th frame, first place the predicted position of the t-1 frame as the center, and place the CNP with different scales from small to large. When the sum of the probability map output by the CNN is higher than a certain threshold, Stop crop, using the current scale as the best search area size. (2) After selecting the optimal search area for the t-th frame, a series of strategies are adopted on the probability map output in the area to determine the final bounding-box center position and size. (3) In terms of model updating, in order to solve the problem of drift caused by inaccurate results of fine-tune, two long-term and short-term CNNs, CNNS and CNNL, were used. The CNNS is updated frequently so that it responds in time to the apparent changes in the target. CNNL updates less, making it more robust to erroneous results. Combine the two to take the most confident result as output. In order to achieve a balance between the adaptation and drift. Summary : SO-DLT, as a successful application of large-scale CNN network in target tracking field, has achieved very good performance: the OPE accuracy plot (0.8819) and OPE success rate have been achieved on the OTB50 dataset proposed by CVPR2013. The success plot reached 0.602. Far beyond the other state of the art. (1) A targeted network structure was designed for tracking issues. (2) Apply CNNS and CNNL to solve the sensitivity of update with the idea of ​​ensemble. Specific parameters are multi-valued and smoothed to solve the sensitivity of parameter values. These measures have now become the killer for tracking algorithms to improve scoring. However, SO-DLT offline pre-training is still using a large number of unrelated pictures. The author thinks that it is a better choice to use timing relevance data that is more in line with the nature of tracking. Since 2015, the application of deep learning in the field of target tracking has created a new trend. That is, the CNN network, such as VGG-Net, trained on a large-scale classification database such as ImageNet is directly used to obtain the feature representation of the target, and then the observation model is used for classification to obtain the tracking result. This approach avoids the predicament of directly training large-scale CNN samples when tracking, and also makes full use of the strong characterization capabilities of depth features. This kind of work has appeared in ICML15, ICCV15, CVPR16. Here are two articles published in ICCV15. FCNT (ICCV15) Visual Tracking with Fully Convolutional Networks One of the highlights of FCNT's use of CNN features in object tracking is the analysis of the performance of CNN features obtained from pre-training on ImageNet. The subsequent network structure is designed based on the analysis results. FCNT mainly analyzes the feature maps of Conv4-3 and Conv5-3 layers of VGG-16, and draws the following conclusions: (1) CNN feature map can be used to track the target location. (2) CNN's many feature maps are noisy or have less relevance to object tracking in distinguishing objects and backgrounds. (3) Different characteristics of CNN have different characteristics. The high-level (Conv5-3) feature is good at distinguishing different types of objects and is very robust to deformation and occlusion of the target, but the ability to distinguish objects within the class is very poor. The lower level (Conv4-3) feature is more focused on the local details of the target and can be used to distinguish similar distractors in the background, but it is not robust to the fierce deformation of the target. Based on the above analysis, FCNT finally formed the frame structure shown in the above figure: (1) Construct the feature selection network sel-CNN (1 layer dropout plus 1 layer convolution) for the Conv4-3 and Conv5-3 features, and select the feature map channel that is most relevant to the current tracking target. (2) Construct the GNet that captures the category information and the SNet that distinguishes the distractor (background similar objects) for the filtered Conv5-3 and Conv4-3 features (both are two-layer convolution structures). (3) Train sel-CNN, GNet, and SNet in the first frame using the given bounding-box heat map regression. (4) For each frame, the above frame predicts that the center crop produces a region, and then inputs GNet and SNet, respectively, to obtain two predicted heatmaps, and determines which heatmap to use based on whether the distractor is used to generate the final tracking result. Summary : FCNT builds a feature screening network and two complementary heat-map prediction networks based on the analysis of different layers of CNN features. Achieving effective suppression of the distractor to prevent the tracker from drifting, while being more robust to the deformation of the target itself, is another successful realization of the ensemble idea. On the OTB50 data set proposed by CVPR2013, the OPE accuracy plot reached 0.856, the OPE success plot reached 0.599, and the accuracy plot was greatly improved. In fact, FCNT's performance on occlusion is not very robust, and existing update strategies still have room for improvement. Hierarchical Convolutional Features for Visual Tracking (ICCV15) This article is the most concise and effective paper that the author used to track using depth features in 2015. Its main idea is to extract the depth features and then use the correlation filter to determine the final bounding-box. This paper briefly analyzes the characteristics of the VGG-19 features (Conv3_4, Conv4_4, and Conv5_4) on target tracking. The conclusions reached are similar to those of FCNT: (1) The high-level features mainly reflect the semantic characteristics of the target and are relatively robust to the apparent changes in the target. (2) The low-level features preserve more fine-grained spatial characteristics and are more effective for the precise positioning of tracking targets. Based on the above conclusions, the author gives a coarse-to-fine tracking algorithm: (1) In the first frame, three correlation filters are obtained by training using the features of Conv3_4, Conv4_4, and Conv5_4 respectively. (2) After each frame, the prediction result of the previous frame is that the center crops out an area, acquires the features of the three convolution layers, performs interpolation, and predicts the two-dimensional confidence score through the correlation filter at each layer. (3) Calculate the maximum response point of the confidence score from Conv5_4 as the center of the predicted bounding box. Then use this position to constrain the search range of the next layer, and make a finer granularity of position prediction downward by layer. The lowest level of forecast results as the final output. The specific formula is as follows: (4) Use the current tracking result to update the correlation filter of each layer. Summary : This article aims at the characteristics of each layer of VGG-19 features, from the coarse-grained to the fine-grained, to accurately locate the center of the target. The OPE accuracy map on the OTB50 dataset proposed by CVPR2013 has reached 0.891, and the OPE success ratio reaches 0.605. Compared with FCNT and SO-DLT, the performance is also quite stable, showing that the depth characteristics are related to the correlation. The great advantage of the filter. However, the correlation filter in this article does not deal with the scale, and assumes that the target scale is unchanged throughout the tracking sequence. The size of the bounding-box finally predicted on a test sequence such as CarScale on a test sequence with very large scale variations differs greatly from the size of the target itself. Both of the above articles are successful cases of applying the pre-trained CNN network to extract features to improve the tracking performance, and demonstrate that it is highly feasible to use this idea to solve the lack of training data and improve performance. However, the pre-trained CNN network of classification tasks pays more attention to the objects in the area classification, ignoring intraclass differences. When the target is tracked, only one object is focused on, and the object and background information are mainly distinguished, and similar objects in the background are obviously suppressed, but it is also necessary to be robust to the change of the target itself. Classification tasks are similar to a common object as a class, and the tracking task is a class with different appearances of the same object, making the two tasks very different. This is also the two articles that fuse multiple layers of features to track to achieve The motivation for better results. The strategies for resolving the insufficiency of training data introduced in 1 and 2 and the tasks tracked by the target itself have some deviations. Is there a better way? The VOT2015 champion MDNet gave a demonstration. This method also achieved an OPE accuracy plot of 0.942 on the OTB50, and an OPE success ratio of 0.702 for an astonishing score. MDNet (CVPR2016) Learning Multi-Domain Convolutional Neural Networks for Visual Tracking Realizing that there is a huge difference between image classification tasks and tracking, MDNet proposes a method for obtaining general target representation capabilities directly from tracking video pre-training CNN. However, there are also problems in sequence training. That is, different tracking sequences track the target completely differently. A certain type of object is a tracking target in one sequence and may be only a background in another sequence. The appearance and the movement pattern of the target itself in different sequences, the illumination in the environment, the occlusion and so on are quite different. In this case, it is difficult to accomplish the task of distinguishing the foreground from the background in all training sequences using the same CNN. Finally MDNet put forward the training idea of ​​Multi-Domain and the Multi-Domain Network shown in the above figure. The network is divided into two parts: a shared layer and a domain-specific layer. That is: Each training sequence is treated as a single domain. Each domain has a second classification layer (fc6) for it. It is used to distinguish the foreground and background of the current sequence, and all layers before the network are shared by the sequence. . In this way, the shared layer achieves the purpose of character expression of the target general in the learning tracking sequence, and the domain-specific layer solves the problem of inconsistent classification targets of different training sequences. During specific training, each mini-batch of the MDNet consists of only a specific sequence of training data, updating only the shared layer and the specific fc6 layer for the current sequence. In this way, the shared layer has the ability to express the common features of the sequence, such as the robustness to light and deformation. MDNet training data is also very interesting, that is, when testing the OTB100 data set, the pre-training is done using 58 sequences that are not coincident in VOT2013-2015. When testing the VOT2014 data set, pre-training was performed using 89 sequences that were not coincident on the OTB100. This alternate use of ideas is also the first time in tracking papers. Online Tracking Phase For each tracking sequence, MDNet mainly has the following steps: (1) Initialize a new fc6 layer randomly. (2) Use the data from the first frame to train the sequence's bounding box regression model. (3) Extract the positive and negative samples with the first frame and update the weights of the fc4, fc5, and fc6 layers. (4) After 256 candidate samples are generated, the one with the highest confidence is selected, and then bounding-box regression is used to obtain the final result. (5) When the confidence level of the final result of the current frame is high, the sample database is sampled and updated, otherwise the model is updated short-term or long-term depending on the situation. MDNet has two points worth learning: (1) MDNet has applied a video data that fits the essence of tracking to do training, and proposes an innovative Multi-domain training method and cross-application of training data. (2) In addition, MDNet draws on many effective strategies from detection tasks, such as hard negative mining and bounding box regression. In particular, the difficulty of regression significantly reduces the problem of tracker drift by focusing on difficult samples in the background (such as similar objects, etc.). These strategies also helped MDNet's OPE accuracy map increase from 0.825 at the beginning of the TPAMI2015 OTB100 data set to 0.908, and the OPE success rate graph was increased from the initial 0.589 to 0.673. However, it can also be found that the overall idea of ​​MDNet is similar to that of RCNN. It needs to forward hundreds of proposals. Although the network structure is small, the speed is still slow. And bounding box regression also requires separate training, so MDNet has room for further improvement. In recent years, RNNs, especially LSTMs with gate structures, GRUs and others have shown outstanding performance in timing tasks. Many researchers began to explore how to use RNN to solve the problems existing in the existing tracking tasks. The following briefly introduces two representative exploration articles in this area. Recurrently Target-Attending Tracking The starting point of this article is more interesting. It is to use a multi-directional recurrent neural network to model and excavate a reliable part that is useful for the overall tracking. It is actually a RNN on a two-dimensional plane. Modeling eventually solves the tracking drift problem caused by the accumulation and propagation of prediction errors. It is also an improvement and exploration of the part-based tracking method and the correlation filtering method. The overall framework of RTT is shown above: (1) First, the candidate areas of each frame are meshed and the HOG features are extracted for each block. Finally, block-based features are connected. (2) After the block feature is obtained, RTT uses the first 5 frames to train the multi-directional RNN to learn the large-scale spatial association between blocks. By pushing forward in four directions, the RNN calculates the confidence of each block, and finally the predicted value of each block constitutes a confidence map of the entire candidate area. Benefit from RNN's recurrent structure, the output value of each block is affected by other associated blocks, compared to only consider the current block is more accurate, to avoid the impact of a single direction on the occlusion, increase the reliability of the target part The impact of the overall confidence map. (3) After the RNN obtains the confidence graph, the RTT executes another pipeline. That is, the correlation filter is trained to obtain the final tracking result. It is worth noting that during the training process, the RNN confidence map weights the filters of different blocks to suppress similar objects in the background and enhance the effect of the reliable part. (4) RTT proposes a strategy for judging whether the current tracking object is occluded, and using it to judge whether it is updated. That is, the confidence level of the target area is calculated and compared with the historical average and the moving average. If the ratio is lower than a certain proportion, it is considered to be blocked, the model update is stopped, and the introduction of noise is prevented. Summary : RTT is the first tracking algorithm to use RNN to model the complex large-scale associations in part-based tracking tasks. The OPE accuracy plot on the OTB50 data set proposed by CVPR2013 was 0.827, and the OPE success ratio reached 0.588. Compared with other correlation filter algorithms based on traditional features, there is a great improvement, indicating that RNN mining of association relationships and constraints on filters are indeed effective. RTT is subject to the influence of the number of parameters. Only ordinary RNN structures with fewer parameters are used (HOG features are actually another compromise in reducing parameters). Combined with the measures to solve the missing training data introduced earlier, RTT can use better features and RNN structure, and there is room for improvement. DeepTracking: Seeing Beyond Seeing Using Recurrent Neural Networks (AAAI16) Specifically, DeepTracking introduces a hidden variable ht with Markov properties, which is believed to reflect all the information of the real environment. The yt that needs to be predicted eventually contains ht, which contains part of ht information, which can be obtained by ht. Let Bt be belief about ht, corresponding to the posterior probability: Bel(ht) = P(yt|ht). Then the timing update from P(yt-1|x1:t-1) to P(yt|x1:t) in the classical Bayesian tracking framework is converted here: Bt = F(Bt-1,xt) and P(ty|x1:t) = P(yt|Bt). The key to giving formal expressions is how to map them to the RNN framework. The core idea of DeepTracking is to use the two weights WF and WP to model F(Bt-1, xt) and P(yt|Bt) respectively, and define Bt as the memory information passed between RNN timings. At this point, as shown in the figure above, the RNN's various states and advancing processes are perfectly matched with the tracking task. In the experimental part, DeepTracking uses simulated 2-dimensional sensor data and the network structure of the 3-layer RNN shown in the figure above. Bt corresponds to the third-layer network output. The task of unsupervised prediction xt+n is used to make the network have the potential to predict yt. Summary : The highlight of DeepTracking's work as a tracking task using RNN modeling is focused on the theoretical modeling of RNN and Bayesian framework fusion. The experiment shows that this method has a good effect in the simulation scenario, but there is a big gap between the simulated data and the real scene. Whether or not it can perform well in practical applications remains to be discussed. This article describes several different ideas for deep learning in the field of target tracking. The three solutions to the lack of training data have their own merits. The author thinks that the method of using sequence pre-training is more relevant to the nature of tracking tasks. Therefore, it is worth paying attention to. (Simane Network and video data training tracking algorithms have recently emerged. For details, see Dr. Wang Naiyan in VLASE. Introduction article on the public number "Object Tracking new ideas"). In general, the RNN-based target tracking algorithm still has much room for improvement. In addition, the existing deep learning target tracking method is still difficult to meet the requirements of real-time, how to design the network and track the process to achieve speed and improve the effect, there is a lot of research space. Acknowledgments : The author of this article would like to thank Anonymous Reviewers and Dr. Wang Nayan, Chief Scientist of Tucson Technology, for their constructive comments on this article. Lei Feng Network (Search "Lei Feng Network" public number attention) Note: This article is authorized by the Deep Learning Lecture Hall to publish it, if you need to reprint please indicate the author and source, not to delete the content. KNM1 Series Moulded Case Circuit Breaker
KNM1 series Moulded Case Circuit Breaker is MCCB , How to select good Molded Case Circuit Breaker suppliers? Korlen electric is your first choice. All moulded Case Circuit Breakers pass the CE.CB.SEMKO.SIRIM etc. Certificates.
Moulded Case Circuit Breaker /MCCB can be used to distribute electric power and protect power equipment against overload and short-current, and can change the circuit and start motor infrequently. The application of Moulded Case Circuit Breaker /MCCB is industrial.
KNM1 series Molded Case Circuit Breaker,KNM1 series Small Size Molded Case Circuit Breaker,KNM1 series Electrical Molded Case Circuit Breaker,KNM1 series Automatic Molded Case Circuit Breaker Wenzhou Korlen Electric Appliances Co., Ltd. , https://www.korlenelectric.com
In recent years, tracking methods based on correlation filtering have attracted many researchers because of their fast speed and good effect. The correlation filter trains filters by returning the input features to the target Gaussian distribution . And find the location of the target in the follow-up tracking to find the peak value of the response in the distribution.
| Target tracking method based on the depth of learning First, the use of auxiliary image data pre-training depth model, fine-tuning online tracking
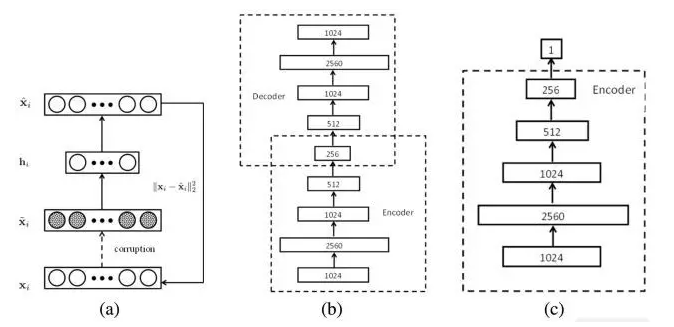
(1) The off-line pre-training data set Tiny Images dataset contains only 3232-size images, and the resolution is significantly lower than that of the main tracking sequence. Therefore, it is difficult for SDAE to learn a sufficiently strong feature representation.

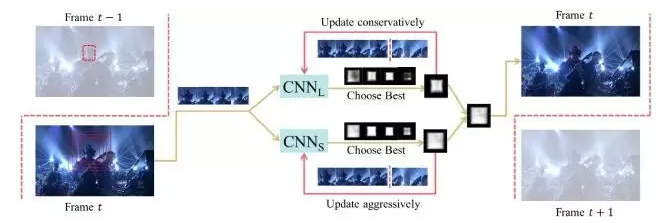
SO-DLT is worth learning from: Second, using the existing large-scale classification data set pre-training CNN classification network to extract features
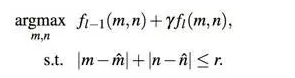
Third, the use of tracking sequence pre-training, fine-tuning online tracking
Fourth, the use of recursive neural network for target tracking new ideas
RTT (CVPR16) 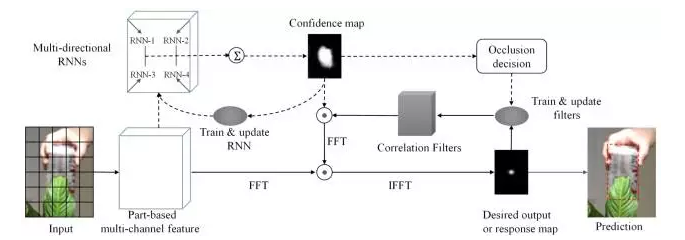
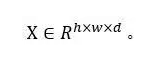
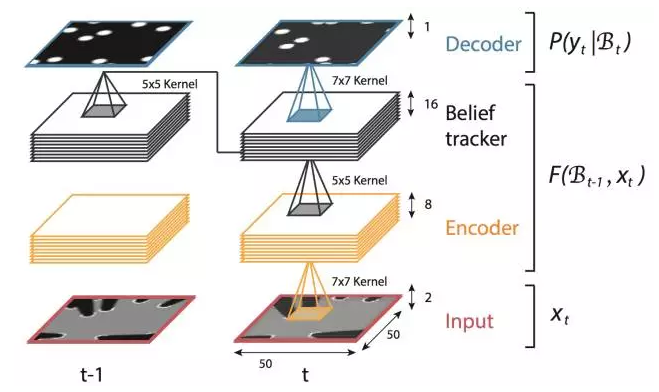
The application scenario of this article is robot vision. The goal is to restore the occluded environmental information obtained by the sensor to real, unobstructed environmental information. Strictly speaking, this article only outputs the restored image. There is no explicit state information such as the position and size of the target. It is not the same as the practice of all the articles introduced earlier. It may be called a new tracking task.
In the aspect of model, unlike RTT, which uses RNN to model two-dimensional plane correlation, DeepTracking uses RNN to do sequence correlation modeling and finally implements an end-to-end tracking algorithm.
Traditional Bayesian tracking methods generally use a Gaussian Kalman filter or discrete sample point weights to approximate the posterior probability P(yt|x1:t) that needs to be solved (yt is needed The predicted real scene around the robot, xt is the scene information directly obtained by the sensor), and its expression ability is limited. DeepTracking extends the traditional Bayesian tracking framework and uses RNN's powerful characterization capabilities to model posterior probabilities. 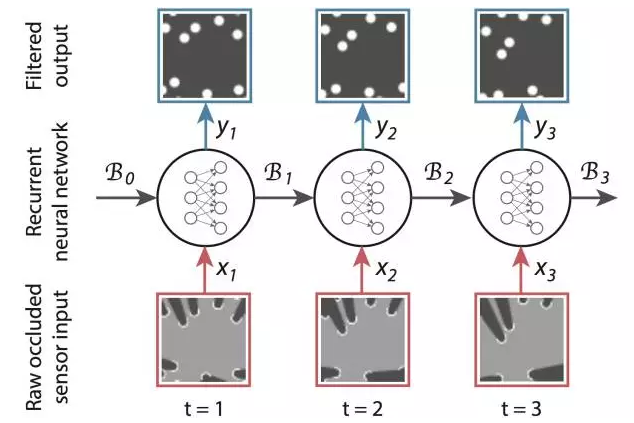

Korlen electric also provide Miniature Circuit Breaker /MCB. Residual Current Circuit Breaker /RCCB. RCBO. Led light and so on .