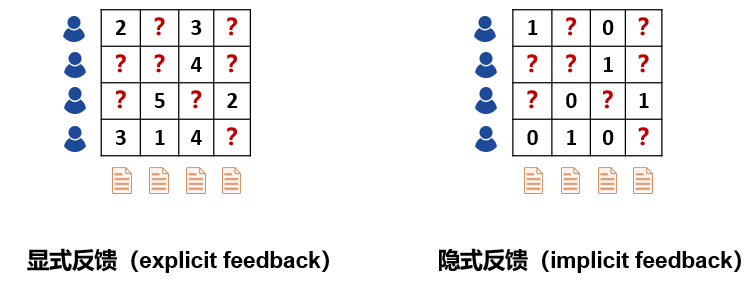
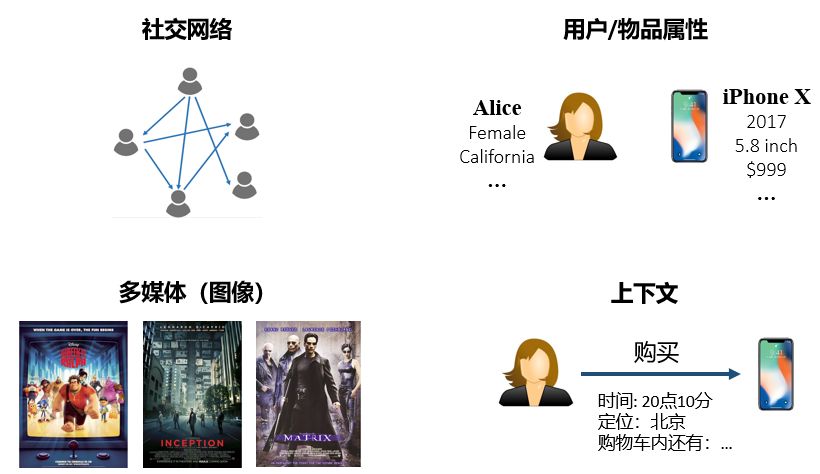
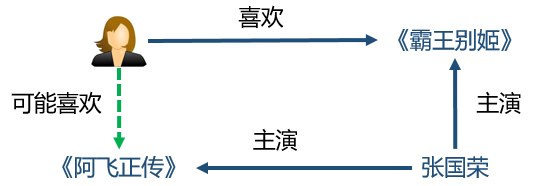
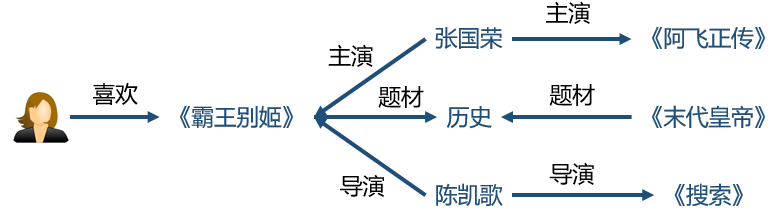
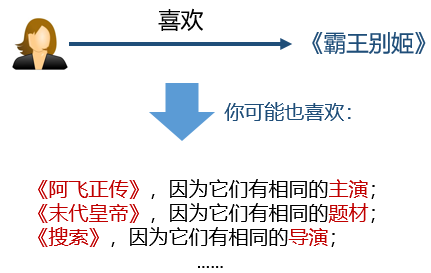
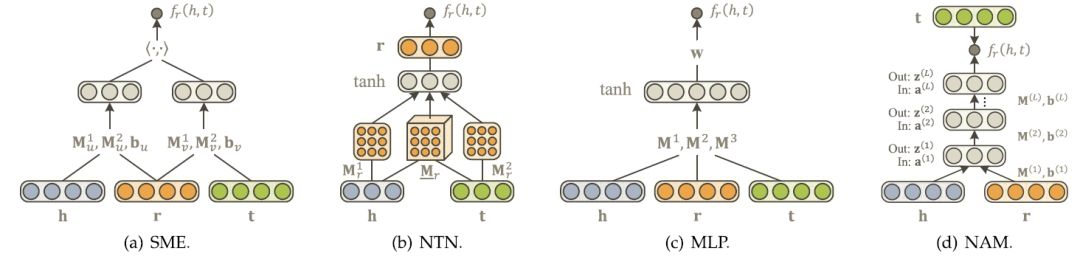
We receive a wide variety of recommendations every day, from news, shopping, to eating, and entertainment. The personalized recommendation system, as an important means of information filtering, can recommend appropriate services based on our habits and preferences. However, the traditional recommendation system is prone to problems of sparsity and cold start. As a new type of auxiliary information, knowledge map has gradually attracted the attention of researchers in recent years. This article will introduce knowledge and knowledge of knowledge map. The possible application value of the map in the recommendation system. Let's learn together! Xiao Wang is a programmer. At eight in the morning, he was awakened by an alarm, picked up his cell phone and started browsing the latest news recommended by the news app on his mobile phone: Later, Xiao Wang remembered that the shoes he had put in his shopping cart last night had not yet placed orders. So he opened a shopping app and checked out his shopping cart: However, he felt that the shoes recommended below seemed more suitable to him, so he bought a pair. After breakfast, Xiao Wang took the subway to work. The boring Xiao Wang on the subway opened a music app. The system has selected the recommended songs for him: After arriving at the company, Xiao Wang began to write code that was not completed, but he could not always adjust the parameters to a satisfactory level. Some annoyed Wang wanted to take a break, so he opened a news app and saw several topics recommended for him: As he carefully read, the manager noticed that he was not working and was very angry. He severely criticized Xiao Wang. Xiao Wang felt very annoyed. At this time, a job search APP in the cell phone sent him a push: Xiao Wang felt that these positions were quite suitable for himself, and he had a plan for a job change. At lunch time, Xiaowang opened a takeaway app and checked out a nearby restaurant recommended by the system: Xiao Wang, while eating a freshly delivered take-away, browses an entertainment app to check out shows recommended for watching with his girlfriend at night: After watching the show in the evening, Xiao Wang and his girlfriend are very satisfied. They think that the app’s system recommendation is great. Recommended system Like Xiao Wang, almost every one of us uses the recommended features of multiple apps every day. Behind these features are personalized recommender systems. With the rapid development of Internet technologies and industries, the number of servers and web pages accessing the Internet has also increased exponentially. The user is faced with massive information. The traditional search algorithm can only present the same item sorting result to the user, and cannot provide corresponding services for different users' interests. Explosion of information makes the utilization of information decrease instead. This phenomenon is called information overload. The referral issue is essentially the replacement of users with items they have never seen, touched or used, including books, movies, news, music, restaurants, tourist attractions, etc. The recommendation system, as an important method of information filtering, is one of the most effective methods to solve the problem of information overload. It is the core technology of user-oriented Internet products. Recommended tasks and difficulties for the system According to different prediction objects, recommendation systems can generally be divided into two categories: one is rating prediction, for example, in movie applications, the system needs to predict the user's rating of the movie, and based on this, it pushes what it may like. the film. The user feedback information in this scenario expresses the user's preference, so this information is also called explicit feedback; the other is click-through rate prediction, for example, in news applications. The system needs to predict the probability of the user clicking on a news item to optimize the recommendation scheme. The user feedback information in this scenario can only express the user's behavioral characteristics (clicks/unclicks) and does not reflect the user's preference, so this kind of information is also called implicit feedback. The traditional recommendation system only uses the historical interaction information (explicit or implicit feedback) of the user and the item as the input. This brings two problems. First, in the actual scene, the interaction information between the user and the item is often very sparse ( Sparse). For example, a movie category APP may contain tens of thousands of movies, but a movie that a user has scored excessively may only have an average of several dozen. Using such a small amount of observed data to predict a large amount of unknown information will greatly increase the overfitting risk of the algorithm. Secondly, because the system does not have historical interaction information for the newly added user or item, it cannot be accurately used. Modelling and recommendation, which is also called the cold start problem. A common idea for solving sparsity and cold-start problems is to introduce some additional side information as input in the recommendation algorithm. Auxiliary information can enrich the description of users and items, enhance the mining ability of the recommendation algorithm, and effectively compensate for sparse or missing information. Common auxiliary information includes: Social networks: A user is interested in an item, and his friend may also be interested in the item; User/Article attributes: Users with the same attributes may be interested in the same type of article; Multi-media information such as images/videos/audio/texts such as product images, movie trailers, music, news headlines, etc.; Context: The time, location, current session information, etc. of the user-item interaction. ...... How to effectively incorporate various auxiliary information into the recommendation algorithm according to the characteristics of the specific recommendation scenario has been a hot and difficult issue in the field of recommendation system research. How to extract effective features from various auxiliary information is also a core issue in the field of recommended system engineering. Knowledge map Among various kinds of auxiliary information, knowledge map as a new type of auxiliary information has gradually attracted the attention of researchers. A knowledge graph is a semantic network. A node represents an entity or a concept. An edge represents various semantic relationships between entities/concepts. A knowledge map consists of several triples (h, r, t), where h and t represent the head and tail nodes of a relation, and r represents the relation. The triad shown above expresses the fact that "Chen Kaige directed Farewell My Concubine", where h = Chen Kaige, t = Farewell My Concubine, and r = director. The knowledge map contains rich semantic associations between entities and provides a potential source of supplementary information for the recommendation system. Knowledge maps have application potential in many recommended scenarios, such as movies, news, attractions, restaurants, shopping, and so on. Compared with other kinds of auxiliary information, the introduction of the knowledge map can make the recommendation result have the following features: Accuracy. The knowledge map introduces more semantic relations for the items, which can deeply discover the user's interests. Diversity. Knowledge maps provide different kinds of relational connections, which are conducive to the divergence of recommendation results and avoid the limitation of recommendation results to a single type. Explainability. The knowledge map can connect the user's history records and recommendation results, thereby improving the user's satisfaction and acceptance of the recommendation results and enhancing the user's trust in the recommendation system. What is worth mentioning here is the difference between the knowledge map and the property of the item. The property of an item can be viewed as a 1-hop node directly connected to an item in the knowledge map, ie, a weakened version of the knowledge map. In fact, a complete map of knowledge can provide deeper and longer-range relationships between items, for example, "Farewell to My Concubine - Leslie Cheung - Hong Kong - Tony Leung - Infernal Affairs". Just because of the higher dimensionality of the knowledge map, the semantic relationship is more abundant, and its processing is therefore more complex and difficult than the item attributes. In general, the existing work that can introduce knowledge maps into the recommendation system is divided into two categories: The generic feature-based methods represented by LibFM [1]. Such methods uniformly use the attributes of the user and the item as inputs for the recommendation algorithm. For example, LibFM remembers all attributes of a user and an item as x, and then makes the interaction intensity y(x) between the user and the item depend on all the first and second items in the property: Based on the generality of this method, we can weaken the knowledge map into the attributes of the article, and then apply this method. Of course, the disadvantages of this approach are also obvious: it is not designed specifically for knowledge maps, and therefore it cannot efficiently use the full information of the knowledge map. For example, it is difficult for this type of method to use multi-hop knowledge, and it is difficult to introduce the information of the relation. Path-based methods represented by PER [2], MetaGraph [3]. This approach treats the knowledge map as a heterogeneous information network and then constructs features based on meta-path or meta-graph between the items. Simply put, meta-path is a specific path that connects two entities. For example, the "actor->movie->director->movie->actor" meta-path can connect two actors, so it can be regarded as a Kind of way to mine potential relationships between actors. The advantage of this type of method is that it fully and intuitively utilizes the network structure of the knowledge map. The disadvantage is that manual meta-paths or meta-graphs need to be designed manually. This is difficult to achieve in practice. At the same time, this type of method cannot be attributed to entities that do not belong. Use in the same domain scenario (such as news recommendation) because we cannot predefine meta-path or meta-graph for such scenarios. Knowledge map feature learning Knowledge Graph Embedding learns a low-dimensional vector for each entity and relationship in the knowledge map while maintaining the original structure or semantic information in the graph. In fact, knowledge map feature learning is a subfield of network embedding, because knowledge map contains unique semantic information, so knowledge map feature learning requires more careful and pertinent model design than general network feature learning. In general, there are two types of models for knowledge map feature learning: Distance-based translational models. This type of model uses a distance-based scoring function to evaluate the probability of a triple, treating tail nodes as the result of head nodes and relational translation. Representatives of such methods are TransE, TransH, TransR, etc.; Semantic-based matching models. This type of model uses a similarity-based scoring function to evaluate the probability of a triple, mapping entities and relationships into implicit semantic spaces for similarity measures. Representative of such methods are SME, NTN, MLP, NAM, and the like. Because knowledge map feature learning learns a low-dimensional vector for each entity and feature, and maintains the structure and semantic information of the original image in the vector, a set of good entity vectors can fully and completely represent entities. Interrelationships, because most machine learning algorithms can easily handle low-dimensional vector inputs. Therefore, using knowledge map feature learning, we can easily introduce knowledge maps into various recommendation system algorithms. In summary, knowledge map feature learning can: Reduce the high dimensionality and heterogeneity of knowledge maps; Enhance the flexibility of knowledge mapping applications; Reduce the workload of feature engineering; Reduce the additional computational burden due to the introduction of knowledge maps. In this paper, we introduce the application value of recommendation system, knowledge map, and knowledge map in recommendation system. As an auxiliary information of the recommendation algorithm, the introduction of the knowledge map can greatly improve the accuracy, diversity, and interpretability of the recommendation system. In the next week's article, we will elaborate on the various ideas and implementations of introducing the knowledge map into the recommendation system. Stay tuned! references [1] Factorization machines with libfm [2] Personalized entity recommendation: A heterogeneous information network approach [3] Meta-graph based recommendation fusion over heterogeneous information networks [4] Knowledge graph embedding: A survey of approaches and applications Digit Segment Led Display,Washing Machine Display,Smd Led Display,Bar Segment Led Display Wuxi Ark Technology Electronic Co.,Ltd. , https://www.arkledcn.com