Research on P2P File Search Mechanism in Wireless Ad-Hoc Network The wireless Ad-Hoc network occupies an extremely important position and has broad application prospects in the field of wireless communication due to its easy construction and support for user mobility. The development of wireless communication technology and mobile technology provides a wider application space for wireless Ad-Hoc network (WANET). P2P networks that often use file sharing are very suitable for WANET. However, the direct application of P2P technology in the existing wireless Ad-Hoc network will cause a large increase in system overhead, low transmission efficiency and low query success rate, thus affecting the performance of the entire network. In the wireless Ad-Hoc network (WANET), it is convenient and fast to realize P2P data sharing and exchange, and improving the file search and download mechanism has become a subject of widespread concern. 2 System Overview Here WANET solves the problem of positioning and querying shared files through a tree-shaped logical structure between nodes, and the tree topology increases as new nodes on the network are added. New nodes can only join WANET through a certain neighbor node. Each WANET provides a unique network ID. In a network with the same ID, each node can only have one parent node. The network has a hierarchical tree topology. This structure helps to find the file path (that is, obtain the route from the node storing the path to the file storage node) to download files from the file storage node. In order to store and retain location information and routing information, the system uses a fully distributed hash table, the key word is the file name of the file to be shared, and the value is the globally uniform location information of the shared file (node ​​MAC address and full path of the node file). One-dimensional space is used to store keyword and hash value pairs, and each keyword is mapped to a corresponding position on the hash chain through a unified hash function. The unified function helps to balance the distribution of information between the nodes. Each node in WANET is responsible for storing a hash chain (corresponding to the index items on the hash table). If a node is responsible for the hash value of a file on the hash chain segment, the node is called a file path node (Pnode), and the node storing the file F is called a file node (Fnode). Therefore, Pnode stores an index carrying location information, and Fnode stores actual files. Therefore, the steps to access a file are as follows: query the file name of the node (Qnode) hash to determine the value on the hash chain; access Pnode (the hash value is included in the hash chain responsible by Pnode); obtain from Pnode Search the location of the file (ie Fnode) and determine the route from the small Pnode to Fnode; get the route from Qnode to Qnode-Fnode, access Fnode, and the file is downloaded from Fnode. 3 Establishment of tree topology and node file positioning Figure 1d shows a WANET network with 7 nodes. In this network, it is assumed that the shared files provided by nodes A, B, C, D, E, F, and G are (α1α2 ), (Β1β2), (γ1), (δ1 δ2), (σ1), (ε1), (η1η2). 3.1 Establishment of tree topology of WANET network system Assuming that there is only one initial node A in the initial stage of network formation, a WANET file sharing network of 7 nodes as shown in FIG. 1d shall be established. The process of establishing tree topology is as follows: (2) Node B (shared files β1, β2) discovers node A and initiates an access request to node A, that is, B wants to join the network formed by A. After node A receives the access request from B, it divides the hash chain it is responsible for into two segments and distributes half of it to B. File α2 therefore falls into the hash chain that node B is responsible for. To B (although the file is still stored in node A, the location information of α2 on A is empty). Therefore, A becomes B's parent node. B stores the position information [α2, A] of the file α2. 4 Search and download process of shared files in WANET network In Figure 1d, suppose D as a query node to search for the file η2, D does not know the location of η2, or even whether the file exists, but the file storage can be known by H (η2) In a node. The search and download process of the shared file η2 file is shown in Figure 4. (1) Node D hashes the file η2 to get H (η2), D finds that H (η2) is not in the hash chain that he is responsible for, and D itself has no child nodes, D passes the query to its only neighbor Node E (E is also D's parent node here). 5 Comparison with flooding system communication overhead WANET is usually used for P2P file sharing, and flooding query is generally used. It is assumed that the flooding model has no selective forwarding function. Therefore, once the flooding query is started in the network, all nodes in the network can receive the query. The system overhead generated by this query is O = (n-1) m, where m represents the number of queries and n represents the number of nodes. The P2P file search and download model in the WANET shared system (Figure 4) forms a tree structure when the network topology is formed, so that even if the file does not exist, it will not cause too many useless query messages like flooding. This structure is almost Can discover and access all shared files on the network. 6 Conclusion In the same size network, on WANET with low mobility and frequent file search, the bandwidth efficiency of the proposed solution is higher than flooding, and file search is more effective. If members of the WANET network move frequently and search files infrequently, flooding is better. In order to avoid flooding and access files through unicast, we try to maintain the consistency of distributed location information. The cost of maintaining the consistency of the location information is compensated by greatly reducing the cost of subsequent file searches. Waterproof Speaker,Waterproof Portable Speaker,Waterproof Wireless Speaker,Outdoor Waterproof Speaker NINGBO SANCO ELECTRONICS CO., LTD. , https://www.sancobuzzer.com
Here is a cross-layer design scheme that unifies the query function and routing function, uses a distributed hash table to establish a tree-like network topology, uses P2P location search technology to distribute file location information among them, and each network member stores and Keep the location and routing information of system resources to realize the location query of shared files. Realize the unification of query and routing functions in WANET, improve the efficiency of file search and download, directionally query network resources, and reduce redundancy overhead. 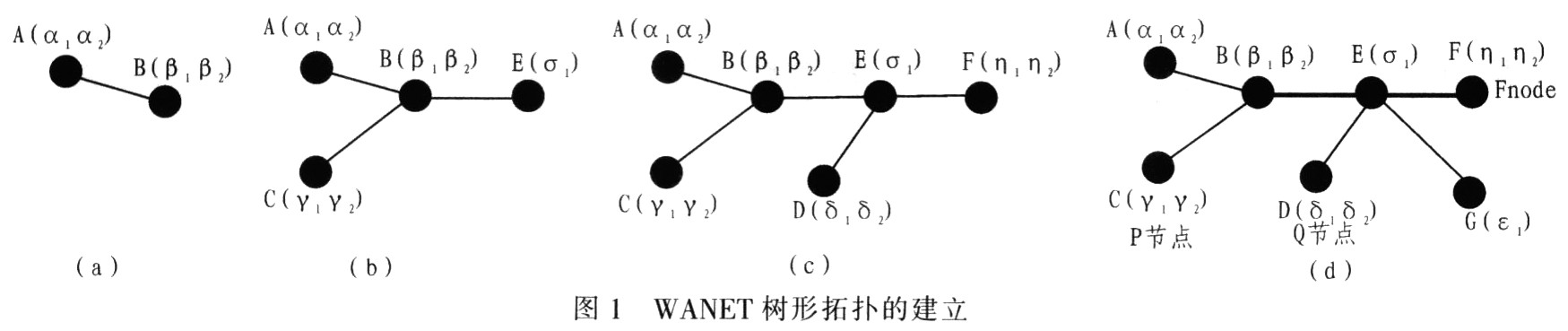
(1) Node A hashes its two shared files α1 and α2 and maps the value to the entire shared file hash chain, as shown in Figure 2a. 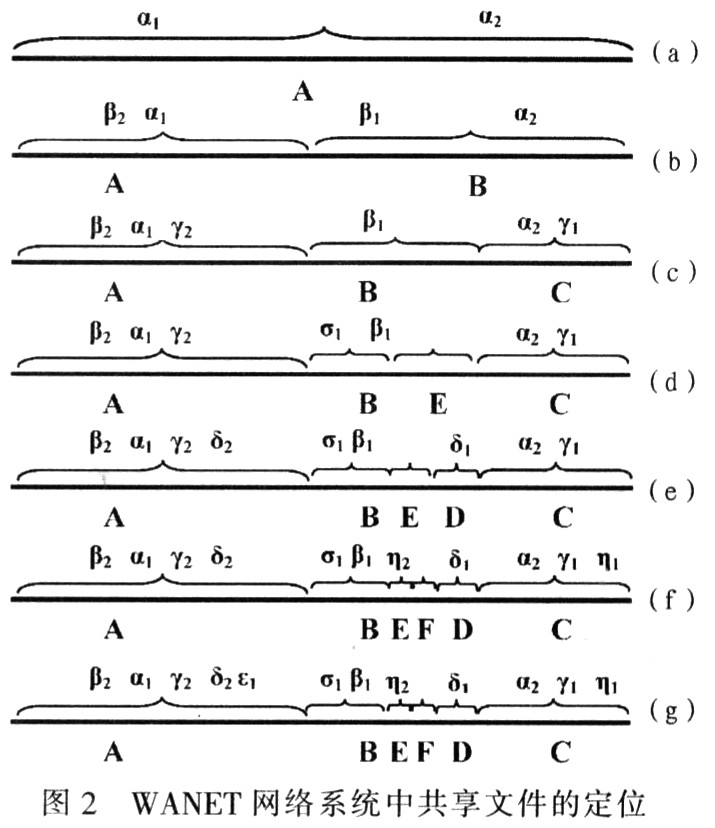
(3) B inserts its shared files β1 and β2 into the network, β1 maps to the hash chain segment responsible for node B, and β2 maps to the hash chain segment responsible for node A. Then the node B stores the location information [β1, B], and the node A stores the location information [β2, B], that is, the Pnode A of the file β1 is the Pnode of the file β2, as shown in FIG.
(4) Another new node C (storage files γ1, γ2) finds node B and sends an access request to it. Node C accesses the network from B, and B divides its hash chain half to C. The files γ1 and γ2 on node C are hashed and mapped onto the hash chain, as shown in Figure 2c. α2 falls into the hash chain segment that C is responsible for. B sends the information of α2 to C. Node C retains not only the location information of α2, but also the path information from C to file α2. C adds B to the path, and saves the index item of [α2, BA]. It indicates that the file α2 is stored in node A, and the path from C to node A is “CBAâ€. Node B becomes C's parent node.
(5) C inserts shared files γ1, γ2 into the network, γ1 maps to the hash chain segment responsible by C, and γ2 maps to the hash chain segment responsible by A.
(6) Similarly, after node E discovers the network and sends an access request to node B, it shares half of the hash chain B is responsible for and inserts file σ1, and B becomes E's parent node; node D (stores files δ1 and δ2) After discovering the network and accessing from node E, half of the hash chain of E is shared, and node F (which stores files η1 and η2) discovers the network and accesses from E, and forks and shares half of the remaining hash chain of E: the last node G (storage shared file ε1) also joined the network from E and shared half of the remaining hash chain of E. In this way, E becomes the parent node of nodes D, G, and F. Each node inserts its own shared file into the network during the process of joining, as shown in Figure 2d ~ Figure 2g, the corresponding shared file is inserted into the hash chain responsible for each node in the network. The corresponding node also stores the file name and routing information to the file storage node.
After the network structure is established, the current location and routing information of each shared file in the network are also located, and the route for searching each shared file can be obtained from the request message to access Pnode, as shown in FIG. 2. The tree topology of the network is also established at the same time, as shown in Figure 1. 
(7) When a child node of the parent node is disconnected, the parent node regains the hash chain segment that the child node is responsible for. Or when the child node is disconnected from its parents, the hash chain of each parent and child node is redistributed from the child node down.
(8) Leaving When a node wants to leave the WANET file sharing network, all shared files must be deleted first, and then its index information is deleted. For example, E will deliver its hash chain to parent B, and at the same time notify its parent B With child nodes D, G, and F, node B adds D, G, and F as child nodes, and nodes D, G, and F use B as a parent node.
In summary, in FIG. 1d, assuming that node D wants to find file η1, D is a query node Qnode, file η1 is stored in node F, then node F is file node Fnode, and file η1 is mapped to H on the hash chain (η1) point, and H (η1) point happens to fall on the hash chain responsible for node C, so node C is the path node Pnode, which stores the routing information from Pnode (node ​​C) to Fnode (node ​​F) .
(2) Node E receives the request of node D to query η2 [η2, D], but the three neighbor nodes B, G, and F of node E do not contain the routing information H (η2) of file η2, and E sends the query To its parent node B.
(3) Because the hash chain responsible for node B also does not contain H (η2), but because node B knows that the hash chain responsible for one of its child nodes (here, node C) contains the requested file name. Hopefully, according to the H (η2) value and the file hash chain status, B forwards the query to node C (otherwise node B sends the query to its parent node A).
After Node B sends the query to Node C, there is no guarantee that C's response will be received. Node C may be connected to other nodes in addition to node B. Therefore, after determining the hash chain where the node is located, C may send a query to one of its child nodes. However, whether node C or its child nodes respond to the query request has no effect on node B. Node B only knows to send the query to node C. In the topology diagram, node C has no child nodes and holds the location information of file η2. The paths that initiate queries from the source node are all identified as queries.
(1) Node C receives the query message [η2, BED], indicating that node D queries the file η2 via nodes E and B, so C generates a query response message ACK [η2, EBC] (including location information) for D, along the path [η2, EBC] returns to node D.
(2) Obtain the routing information FED of the file node Fnode from node C and send it back to node D along the route of the querying node. Node C transmits the response to the next node B on the path.
(3) After viewing the route in the response, Node B sends the message to the next node E in the path.
(4) E checks the route and sends the message to file node F (storage node of file η2) in the path.
(5) Node D receives the query response, and the response message contains the location information of file η2 [η2, DEF]. Now, node D not only knows that file η2 exists in node F, but also knows two paths from D to C (including η2 file location information) and from C to F (η2 file storage node). Node D links the path to DEBCBEF, then deletes the unnecessary path EBCB, and finally forms the path DEF from D to η2, that is, the path from the query originating node D to the storage node F of the file η2, through which it can be directly found from node F And download the file η2. 
and so. Once the network is established. Compared with flooding, the cost of a single query is significantly more cost-effective.
On the other hand, due to the large system overhead caused by recovery operations and network access operations, each time a network disconnection and network access occurs, additional overhead will be incurred (the child nodes disconnected during the recovery operation become the root Nodes, hash chains are redistributed in the entire sub-network; when accessing the network, each accessing node needs to perform an insert request on the shared file in the entire network, which generates a lot of communication traffic), but flooding will not bring Such overhead.
When a message does not exist, every file on every node in the network will be flooded and cause congestion. The WANET file sharing system allows low mobility of members, and a more complete network structure after re-hashing can offset the increase in query costs caused by mobility.