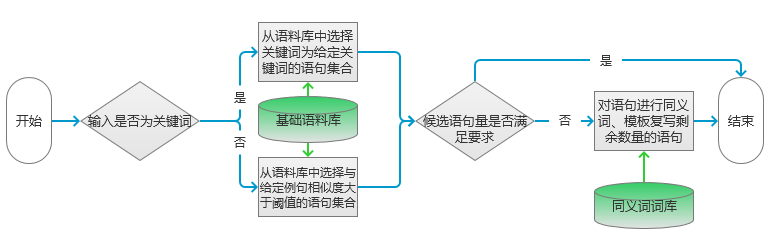
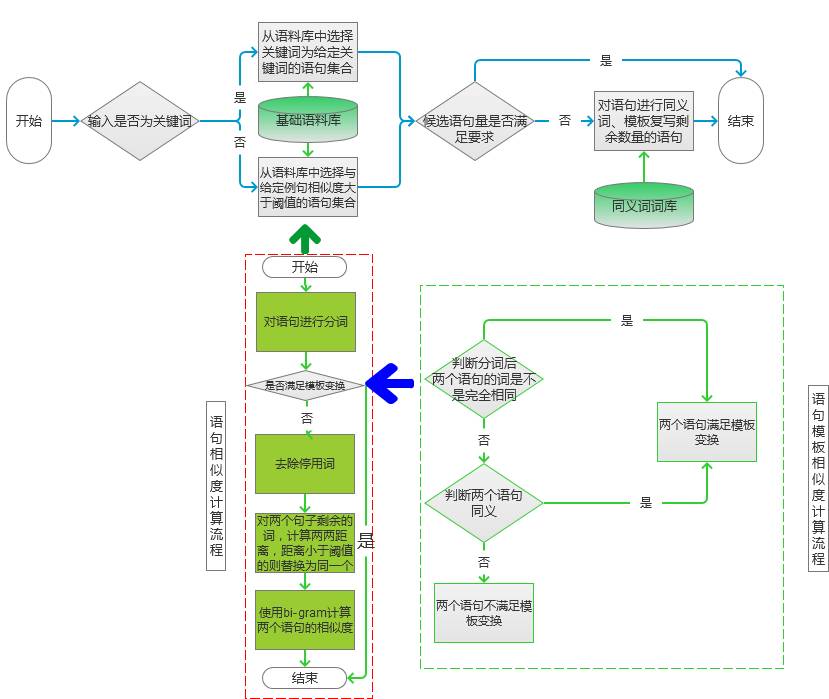
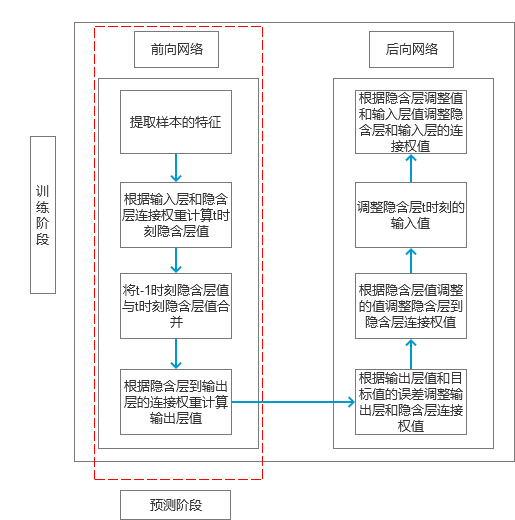
This chapter is taken from the book "Introduction and Practicality of Natural Language Processing Technology." One of the most significant applications in natural language processing (NLP) is automated text generation. Tasks such as keyword extraction, phrase identification, and automatic abstract creation fall under this category. However, these methods are often limited in their scope. In this section, we introduce a more advanced application: generating text from small to large inputs, including sentence rewriting and creating full articles or paragraphs based on keywords or topics. Automatic Text Generation Based on Keywords The first part of this chapter outlines techniques for generating a piece of text using keywords. These techniques primarily involve keyword extraction and synonym recognition. Below is a detailed explanation of the implementation process. Scenarios When working on search engine advertising, it's common to need a concise ad description. Typically, the input is a set of keywords. For example, if the ad is for flowers and the keywords are "flowers" and "cheap," the model should generate several candidate descriptions. In some cases, the input may be a sentence rather than keywords. For instance, a manually written example could be: "This weekend, white flowers are only 99 yuan, and they also include free shipping!" Based on this, we aim to generate alternative expressions with similar meanings. Here, we present a keyword-based one-sentence text generation model. Principles The model’s processing flow is illustrated in Figure 1. Figure 1 Depending on the type of input, different processing steps are applied. If the input is keywords, the system selects sentences from the corpus that match those keywords. If the input is a sentence, the system finds similar sentences in the corpus with a similarity above a certain threshold. Keyword extraction in the corpus uses the method described earlier. The specific algorithm can vary depending on the corpus. Figure 2 Sentence similarity is calculated following the flow in the dotted box on the left side of Figure 2. First, the two sentences are segmented into words. If the segmented sentences meet the template transformation condition, they are added directly to the candidate set with a similarity score of 0. Otherwise, proceed to step c). To determine if two sentences meet the template transformation condition, check if the words are not identical but only differ in position. If so, the condition is met. If not, check if synonym replacement is possible between the words. If synonyms can be used, the transformed sentences are compared again. If all conditions fail, the sentences do not meet the template transformation requirement. For remaining words, calculate the word distance. For example, if sentence 1 has "flowers," "how much money," "package," and sentence 2 has "flowers," "cheap," "free shipping," the distance matrix would look like this: After replacing similar words, the word vectors become: sentence 1: Construct bi-gram statistical vectors for both sentences: (1) sentence 1: The similarity is calculated using the formula: So the similarity of the example is: 1.0 - 2.0 * 2 / 8 = 0.5. Once the candidate sentences are extracted, the next step depends on the number of candidates. If there are enough, select the top ones by similarity. Otherwise, rewrite the sentences using synonym replacement and templates. Implementation The code for calculating candidate sentences is as follows: Map if (type == 0) { // input as keyword result = getKeyWordsSentence(keyWordsList); } else { result = getWordSimSentence(sentence); } if (result.size() >= number) { result = sub(result, number); } else { result = add(result, number); } The key here is processing the corpus, filtering similar keywords and sentences. For keyword screening, the Bloom filter is used, though other methods like index lookup can also work. For candidate sentences, initial screening is done using keywords, followed by similarity calculations. The results are stored in a map, where the key is the sentence and the value is its similarity. Sorting is done from low to high similarity. Code for sentence similarity filtering: for (String sen : sentenceList) { List List boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2); if (!isPatternSim) { double tmp = getBigramSim(wordsList1, wordsList2); if (threshold > tmp) { result.put(sen, tmp); } } else { result.put(sen, 0.0); } } The process involves segmenting the sentences and checking for template transformations. If satisfied, the sentence is added with a minimum similarity score. Otherwise, bi-gram similarity is calculated and filtered based on a threshold. The bi-gram calculation here is optimized to avoid issues with varying lengths. Similarity measures can be adjusted based on the specific use case. Expansion This section covers text-to-text generation, which includes tasks like summarization, sentence compression, rewriting, and fusion. Techniques in both summaries and sentence rewriting are discussed. Summarization involves keyword extraction, phrase extraction, and sentence selection. Sentence rewriting can be done through synonym replacement, template-based methods, or statistical models. Synonym-based rewriting ensures semantic consistency but may reduce fluency. Template-based methods use predefined structures, offering speed but limiting flexibility. Statistical and semantic models rely on large datasets and prior knowledge, allowing for better structure but requiring extensive training data. RNN Model for Automatic Text Generation Section 6.1.2 describes techniques for generating long text from short input. The main tool used here is the RNN network, which processes sequences to auto-fill text. Below is a detailed explanation of the implementation. Scenarios In advertising, you might need to generate a paragraph from a single sentence or a few keywords. The output length is typically between 200 and 300 words. To achieve this, an RNN algorithm is used. This algorithm was introduced in Section 5.3 for converting pinyin to Chinese characters. The principle is similar: given input, generate the next element in the sequence. Principles As in Section 5.3, the Simple RNN model is used. The entire calculation process is shown in Figure 3. Figure 3 During feature selection, the model considers the relationship between segments, paragraph length, emotional shifts, and wording changes to ensure natural transitions. Adjectives and adverbs can be used more frequently to enhance appeal without altering the structure. Words related to the topic should be repeated to maintain consistency and increase exposure. These strategies are particularly useful in advertising scenarios, though other contexts may require different optimizations. The specific calculation process is similar to Section 5.3 and will not be repeated here. Code The code for feature training is as follows: public double train(List alreadyTrain = true; double minError = Double.MAX_VALUE; for (int i = 0; i < totalTrain; i++) { double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length]; double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length]; double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length]; List List double[] hiddenLayerInitial = new double[hiddenLayers]; Arrays.fill(hiddenLayerInitial, 0.0); hiddenLayerInput.add(hiddenLayerInitial); double overallError = 0.0; overallError = propagateNetWork(x, y, hiddenLayerInput, outputLayerDelta, overallError); if (overallError < minError) { minError = overallError; } else { continue; } first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length); double[] hidden2InputDelta = new double[weightLayerh_update.length]; hidden2InputDelta = backwardNetWork(x, hiddenLayerInput, outputLayerDelta, hidden2InputDelta, weightLayer0_update, weightLayer1_update, weightLayerh_update); weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha)); weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha)); weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha)); } return -1.0; } The variables are initialized, and the forward network predicts the input values. Then, the backward network adjusts the weights based on the prediction error. Each update is scaled by the learning rate alpha. The code for prediction is as follows: public double[] predict(double[] x) { if (!alreadyTrain) { throw new IllegalAccessError("model has not been trained, so cannot be predicted!!!"); } double[] x2FirstLayer = matrixDot(x, weightLayer0); double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh); if (x2FirstLayer.length != firstLayer2Hidden.length) { throw new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!"); } for (int i = 0; i < x2FirstLayer.length; i++) { firstLayer2Hidden[i] += x2FirstLayer[i]; } firstLayer2Hidden = sigmoid(firstLayer2Hidden); double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1); hiddenLayer2Out = sigmoid(hiddenLayer2Out); return hiddenLayer2Out; } Before predicting, the model must be trained. If not, an error is thrown. After training, the forward network calculates the output, and the final result is chosen based on the highest probability. Expansion Text generation can be categorized into the following types based on input: 1. Text-to-text: Input is text, output is text. 2. Image-to-text: Input is an image, output is text. 3. Data-to-text: Input is data, output is text. 4. Other: Input is not any of the above, but output is text. Among these, image-to-text and data-to-text have seen rapid development, especially with advancements in deep learning and knowledge mapping. GAN-based technologies can now generate accurate text descriptions from images and even create images from text inputs. Text generated from data is commonly used in news writing, with notable progress in both English and Chinese. While these systems are not purely data-driven, they combine multiple approaches. Technically, two main methods exist: symbol-based (knowledge maps) and statistic-based (learning patterns from text). With the integration of deep learning and knowledge maps, these methods are converging, promising future breakthroughs in NLP technology.
The Mylar Speaker solutions come in a variety of shapes
and sizes. We can provide various mounting configurations and performance
alterations to fit any industrial application. Our Mylar speakers produce excellent sound output (dB) at specified frequency
ranges. The unique characteristics of a Mylar cone allow us to keep tight
tolerances during the manufacturing process. Additionally, Mylar is easily and
consistently moldable, creating a cost-effective solution, time after time.
It`s also beneficial in applications that are exposed to excessive moisture or
humidity since Mylar has a high resistance to environmental factors.
Mylar Speaker,Mylar Tweeter,Mylar Cone Speaker,Cellphone Mylar Speaker Jiangsu Huawha Electronices Co.,Ltd , https://www.hnbuzzer.com