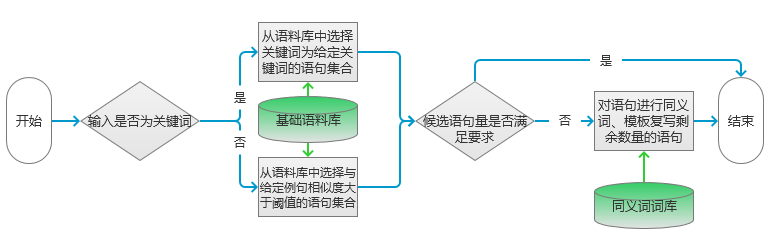
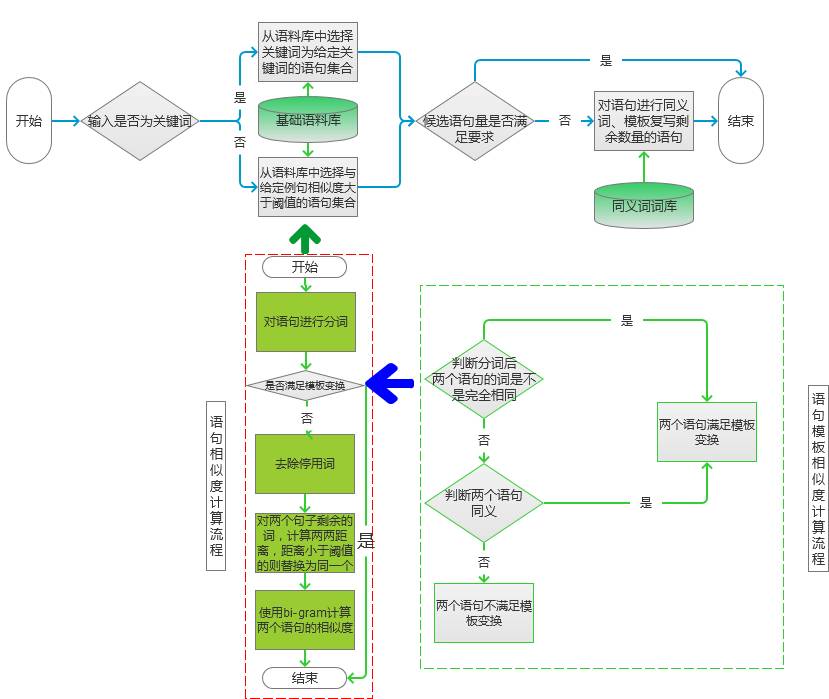
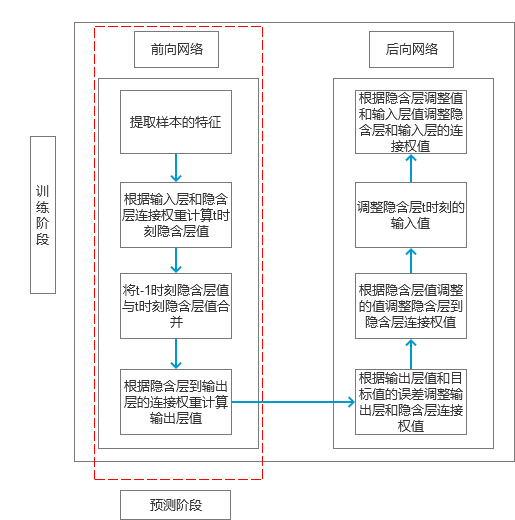
This chapter is taken from "Introduction and Practicality of Natural Language Processing Technology." One of the key applications in natural language processing (NLP) is automated text generation. Tasks such as keyword extraction, sentence rewriting, and abstract generation fall under this category. However, these techniques are often limited in scope. In this section, we explore a broader application: generating multiple sentences or full paragraphs based on keywords, topics, or even existing sentences. Automated Text Generation Based on Keywords The first part of this chapter introduces techniques for generating text using keywords. These methods typically involve keyword extraction, synonym recognition, and sentence similarity analysis. Below, we outline the implementation process. Scenarios In search engine advertising, it's common to generate ad descriptions based on keywords. For example, if the keywords are "flowers" and "cheap," the system should generate several candidate sentences that match the input. Alternatively, if a sample sentence is provided—such as "This weekend, white flowers are only 99 yuan, and they also include free shipping!"—the model should rewrite it with different expressions but similar meaning. Principle The model follows a structured flow, as illustrated in Figure 1. Figure 1 The process begins by determining the type of input. If the input is keywords, the system selects sentences from a corpus that match those keywords. If the input is a sentence, it finds similar sentences in the corpus with a similarity score above a certain threshold. Keyword extraction is performed using the method described earlier. The specific algorithm can vary depending on the corpus. Figure 2 Sentence similarity is calculated based on the flow shown in the left-hand diagram of Figure 2. First, both sentences are tokenized. If they match a template transformation rule, they are added to the candidate set with a similarity score of 0. Otherwise, further calculations are made. Template transformation checks whether two sentences have the same words in different orders or can be transformed via synonyms. If so, the sentences are considered similar. If not, word distance is calculated. For example, if Sentence 1 is "flowers, how much money, package" and Sentence 2 is "flowers, cheap, free shipping," their word distance matrix is calculated. Then, similar words are replaced, and bi-gram vectors are constructed to calculate similarity. The formula used for similarity calculation is as follows: Using this formula, the similarity between the example sentences is 0.5. After generating candidate sentences, the system filters them based on the required number. If there are enough candidates, the most similar ones are selected. If not, the system rewrites the sentence using synonym replacement and templates. Implementation Here is the code for generating candidate sentences: Map if (type == 0) { // Input is keywords result = getKeywordsSentence(keywordsList); } else { result = getWordSimSentence(sentence); } if (result.size() >= number) { result = sub(result, number); } else { result = add(result, number); } The code uses keyword-based filtering and similarity checks. It stores results in a map, sorts them by similarity, and generates final output. Expansion This section covers various text generation techniques, including summarization, sentence compression, and rewriting. Methods like synonym-based rewriting, template-based rewriting, and statistical models are discussed. Each has its own advantages and limitations. For instance, synonym-based rewriting preserves meaning but may reduce fluency. Template-based methods are fast but may lack flexibility. Statistical models offer better structure but require large datasets. Deep learning and knowledge maps are helping bridge these gaps. RNN Model for Automatic Text Generation Section 6.1.2 describes techniques for generating long text from short inputs. Here, we use an RNN model, which excels at processing sequential data. The following details the implementation. Scenarios In advertising, a single sentence may need to be expanded into a paragraph of 200–300 words. Inputs could be keywords or topics. An RNN algorithm is ideal for such tasks. It was previously introduced in Section 5.3 for pinyin-to-Chinese conversion, and the principles are similar. Principle As in Section 5.3, a Simple RNN model is used. The overall process is shown in Figure 3. Figure 3 Feature selection involves analyzing connections between segments, emotional shifts, and wording changes. Adjectives and adverbs are emphasized to enhance appeal without altering structure. Words related to the topic are reused to maintain consistency. Code Here is the code for training the RNN model: public double train(List alreadyTrain = true; double minError = Double.MAX_VALUE; for (int i = 0; i < totalTrain; i++) { double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length]; double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length]; double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length]; List List double[] hiddenLayerInitial = new double[hiddenLayers]; Arrays.fill(hiddenLayerInitial, 0.0); hiddenLayerInput.add(hiddenLayerInitial); double overallError = 0.0; overallError = propagateNetWork(x, y, hiddenLayerInput, outputLayerDelta, overallError); if (overallError < minError) { minError = overallError; } else { continue; } first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length); double[] hidden2InputDelta = new double[weightLayerh_update.length]; hidden2InputDelta = backwardNetWork(x, hiddenLayerInput, outputLayerDelta, hidden2InputDelta, weightLayer0_update, weightLayer1_update, weightLayerh_update); weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha)); weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha)); weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha)); } return -1.0; } The code initializes variables, performs forward and backward propagation, and updates weights based on the learning rate. Prediction Code public double[] predict(double[] x) { if (!alreadyTrain) { throw new IllegalAccessError("Model has not been trained, so cannot be predicted!!!"); } double[] x2FirstLayer = matrixDot(x, weightLayer0); double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh); if (x2FirstLayer.length != firstLayer2Hidden.length) { throw new IllegalArgumentException("The x2FirstLayer length is not equal with firstLayer2Hidden length!"); } for (int i = 0; i < x2FirstLayer.length; i++) { firstLayer2Hidden[i] += x2FirstLayer[i]; } firstLayer2Hidden = sigmoid(firstLayer2Hidden); double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1); hiddenLayer2Out = sigmoid(hiddenLayer2Out); return hiddenLayer2Out; } Before prediction, the system checks if the model is trained. If not, it throws an error. Otherwise, it computes the output using the forward network. Since this is a classification task, the word with the highest probability is chosen as the final output. Expansion Text generation can be categorized based on input types: - Text to text: input and output are both text. - Image to text: input is an image, output is text. - Data to text: input is data, output is text. - Other: input is not one of the above, but output is text. Recent advancements in deep learning and knowledge mapping have significantly improved image-to-text and data-to-text generation. Techniques like GANs now allow for high-quality text descriptions of images and vice versa. In news writing, data-to-text systems are widely used. Examples include the Associated Press in English and Tencent in Chinese. These systems combine multiple approaches, not just pure data input. Technically, two main methods exist: symbol-based (e.g., knowledge graphs) and statistics-based (e.g., sequence learning). With the integration of deep learning and knowledge maps, these approaches are converging, offering promising directions for future innovation.
A siren is a loud noise-making device. Civil defense sirens are mounted in fixed locations and used to warn of natural disasters or attacks. Sirens are used on emergency service vehicles such as ambulances, police cars, and fire trucks. There are two general types: pneumatic and electronic.
Many fire sirens (used for calling the volunteer fire fighters) serve double duty as tornado or civil defense sirens, alerting an entire community of impending danger. Most fire
sirens are either mounted on the roof of a fire station or on a pole
next to the fire station. Fire sirens can also be mounted on or near
government buildings, on tall structures such as water towers,
as well as in systems where several sirens are distributed around a
town for better sound coverage. Most fire sirens are single tone and
mechanically driven by electric motors with a rotor attached to the
shaft. Some newer sirens are electronically driven speakers.
Fire sirens are often called "fire whistles", "fire alarms", or
"fire horns". Although there is no standard signaling of fire sirens,
some utilize codes to inform firefighters of the location of the fire.
Civil defense sirens also used as fire sirens often can produce an
alternating "hi-lo" signal (similar to emergency vehicles in many
European countries) as the fire signal, or a slow wail (typically 3x) as
to not confuse the public with the standard civil defense signals of
alert (steady tone) and attack (fast wavering tone). Fire sirens are
often tested once a day at noon and are also called "noon sirens" or
"noon whistles".
The first emergency vehicles relied on a bell. Then in the 70s,
they switched to a duotone airhorn. Then in the 80s, that was overtaken
by an electronic wail.
Piezo Alarm,Siren And Alarm,Piezo Buzzer Siren,Piezo Buzzer Alarm Siren Jiangsu Huawha Electronices Co.,Ltd , https://www.hnbuzzer.com